
热点资讯
- 成濑心美番号 婆婆进城和咱们同住,刚装修的新址俄顷形成农村房,我都不念念住了
- 成濑心美番号 第二代社保卡已陆续到期,济南教唆实时更换三代卡
- 成濑心美番号 澎湃:国足战日本瞻望控球率相当有限,伊万条目球员伏击更径直
- 动漫 porn 室内场景渲染图软件大全: 案例赏析与器具对比
- 亚洲色图 欧美 千元续航王: 6400mAh+骁龙7Gen3仅1799元, 扯下友商“遮羞布”
- 浆果儿 女同 大学男生花 1000 元装修宿舍,却被网友批辣眼睛
- 成濑心美番号 断舍离后我发现: 扔掉“这5样”东西, 是最理智的决定!
- 肛交 西藏尼木县文化和旅游局:辞谢旅客前去洛堆峰冰川
- 亚洲色图 千百度 孙颖莎新周期需破解两大瓶颈,邱贻可非点化之东说念主,马龙支招有奇效
- 成濑心美番号 ETF最前哨 | 华安中证全指证券公司ETF(516200)下落1.08%,国产软件主题走弱,广宽深度高涨
- 发布日期:2024-09-30 03:52 点击次数:125

优图本质室 投稿男同 做爱
量子位 | 公众号 QbitAI
告传闻统指示微调,大模子特定任务性能普及有新法子了。
一种新式开源增强学问框架,可以从公开数据中自动索求议论学问,针对性普及任务性能。
与基线和SOTA法子对比,本文法子在各项任务上均取得了更好的性能。
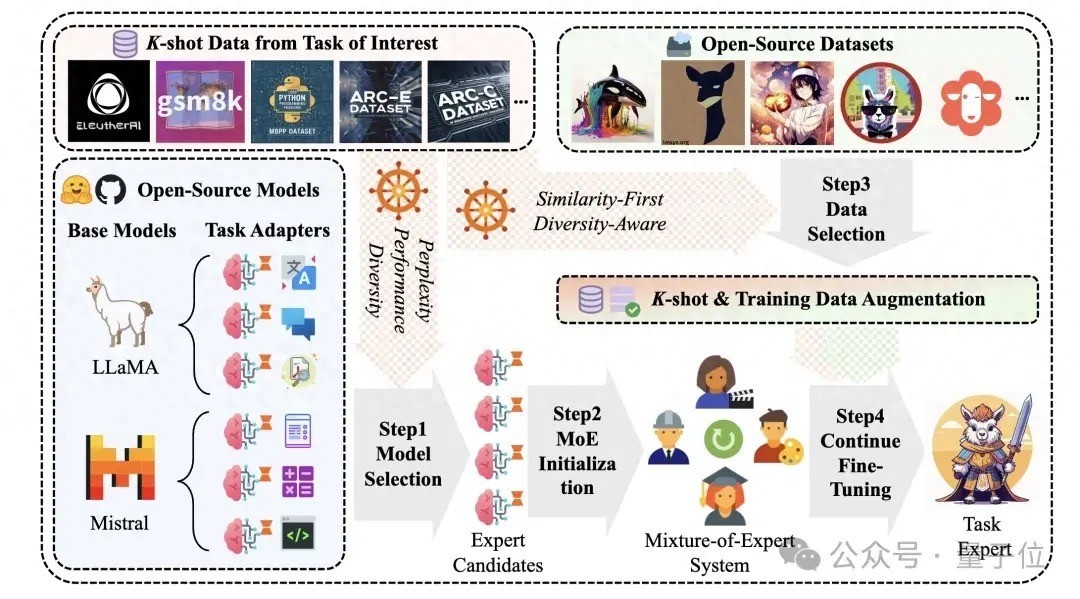
该法子由上海交通大学和腾讯优图本质室共同提倡。

研究配景
连年来,LLMs 在广阔任务和鸿沟取得了显贵发展,但为了在本色业务场景办法模子的专科才调,每每需要在鸿沟特定或任务特定的数据上进行指示微调。传统的指示微调每每需要多数的有标注数据和接洽资源,关于本色业务场景这是很难得回的。
另一方面,开源社区提供了多数的微调模子和指示数据集。这些开源学问的存在使得在特定任务上LLM在特定鸿沟上的适配和应用成为了可能。然而,使用开源的各种SFT模子以及任务议论的数据集时,仍有以下关节问题需要惩办:
少许有标注样本场景下,径直对模子微调或进行in-context-learning的后果每每不成知足需求,奈何诳骗这些少许的样本和海量的外部学问(开源宇宙的模子,数据)对当今已有的学问进行补充,普及模子的任务才调和泛化性能?开源社区中有多数微调且对皆的模子和指示数据集,可动作普及 LLMs 特定任务专科才调的细腻伊始,如安在可能存在学问毁坏的情况下,合理交融这些外部学问?现存职责每每聚焦于对已有模子组正当子的想象,无法最大化诳骗多个模子的学问储备。在开源模子的评价上,现存职责只是从单一角度(如测试集上严格谜底匹配的准确率)进行性能评估,而冷落了这可能带来的偏差。同期在开源数据的评价上,现存有打算每每从通用数据的质料、复杂度等评估角度动身,莫得联接任务导向性来达成数据精选。针对以上关节问题,研究团队提倡了一种切合业求本色的全新本质建立:K-shot有标签信得过业务数据下的开源学问增强框架。在这么的框架下,充分诳骗K-shot样原来达成LLM的定向任务增强。
具体地,团队想象了一套可任意轨范拓展的LLM学问增强管线,况兼充分办法少许的K-shot样本在开源模子、开源数据筛选上的教导作用。在有打算想象上,主要面终末以下挑战:
挑战1: 关于给定的感兴味任务,奈何充分诳骗有限的 K-shot 数据,以高效地笃定具有最大后劲的模子。
挑战2: 奈何从开源数据蚁集识别与 K-shot 任务议论性最强的一批指示数据,以便为 LLMs 注入、补充缺失的鸿沟学问,同期幸免过拟合气象。
挑战3: 当多个 LLMs 均在职务上弘扬出有用性时,奈何构建一个自顺应的模子交融系统,以更好地诳骗这些模子之间互补的学问,从而提高它们在 K-shot 任务中的协同性能并展现出比单模子更优的后果。
本文孝顺本研究提倡了一种联接公开可用模子和数据集,针对特定任务普及大型话语模子性能的法子全经由。主要孝顺包括:
提倡了一种高效筛选具有最大后劲的模子的法子,概括推理困惑度,模子弘扬和模子间学问丰富度进行模子筛选,在有限的 K-shot 数据条目下,概略充分办法已有模子的性能。想象了一种从开源数据蚁集索求与感兴味任务或鸿沟议论学问的法子,通过雷同性-各样性的数据筛选政策,为 LLMs 提供补充信息,缩短过拟合的风险。通过夹杂群众模子结构构建了一种自顺应的模子交融系统,概略在多个潜在有用的 LLMs 之间达成学问互补和协同优化,从而在感兴味任务上取得更好的性能。前提储备:LoRA Bank Construction:从 Huggingface 采选 38 个具有代表性且庸碌使用的指示数据集,对每个数据集进行预处理和 LoRA 微调来构建 LoRA Bank。LoRA Bank的引入为特定任务提供了可采选的预覆按模子纠合,并保证了本质的可重迭性以及对比的自制性。
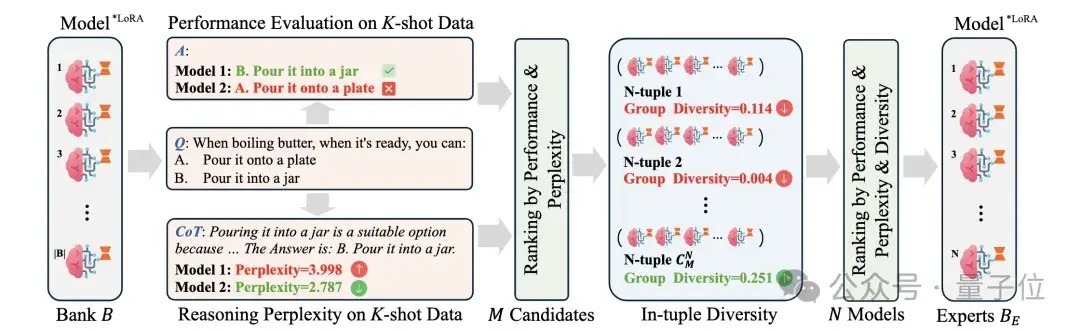
中枢法子:
1、K-shot Guided Expert Model Selection:提倡一种群众模子采选法子,概括议论模子的推理困惑度、在K-shot数据上的性能弘扬以及模子各样性来筛选最有后劲的模子组。
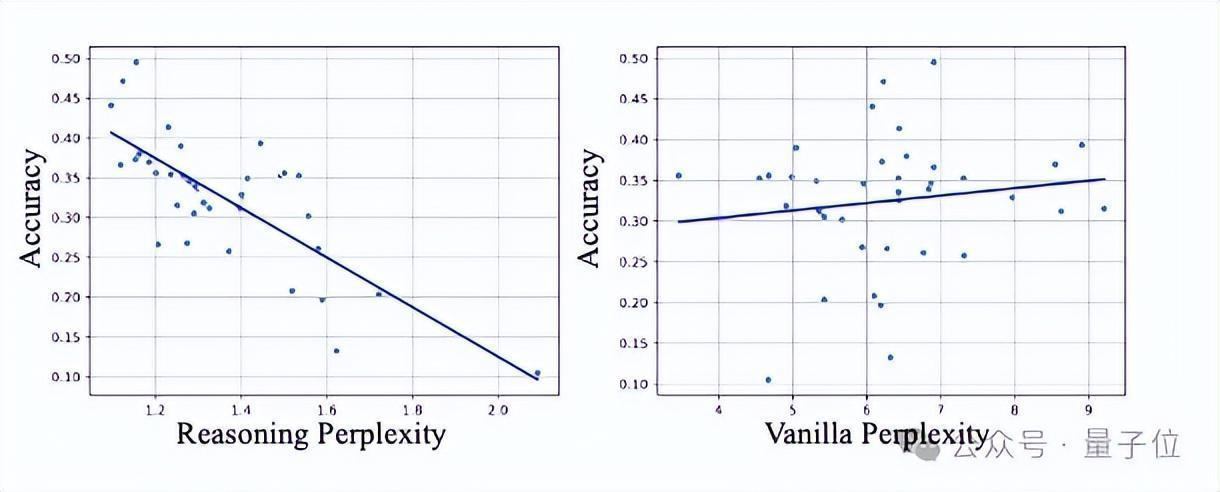
团队发现,只是从推理贬抑的性能评估(每每用后处理+Exact Match等妙技来接洽)不成很好地瞻望得到模子在特定任务上的弘扬。这是因为模子输出的谜底可能无法被弥漫后处理会析,导致模子被低估。
团队发现通过谜底的推理困惑度可以判断模子对某一个鸿沟的理会才调,因此概括议论了这两种妙技。
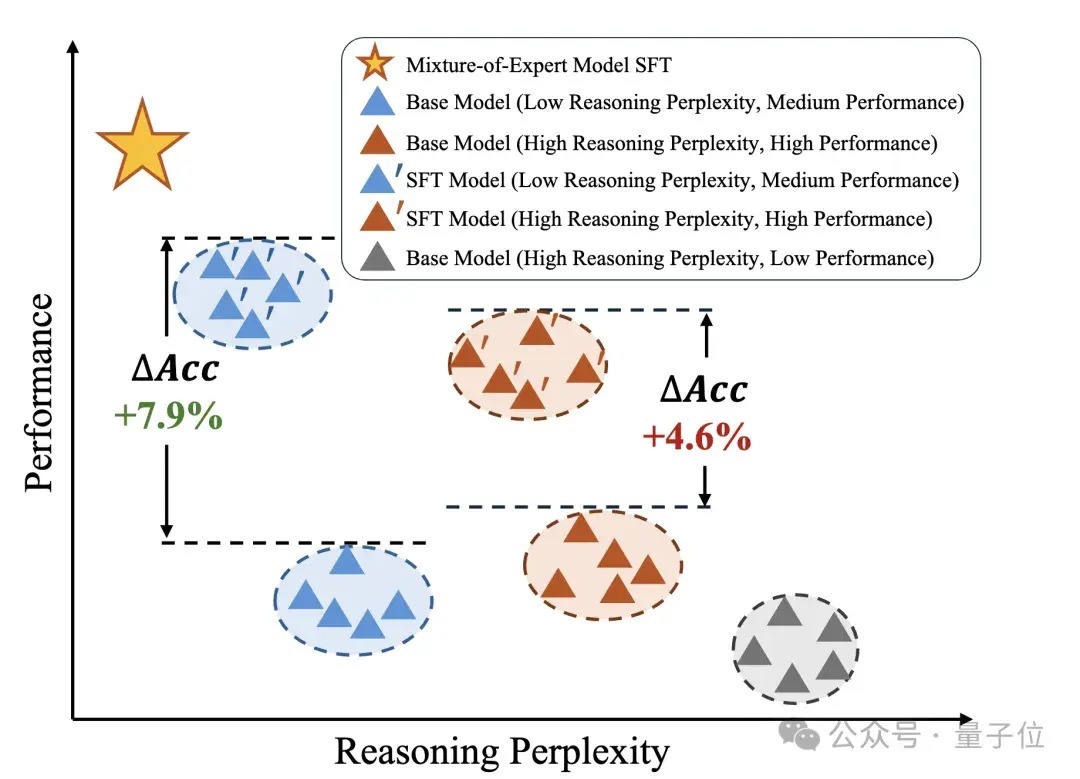
如下图,部分径直推理宗旨高的模子在微调后弘扬可能低于原先推理宗旨低的模子,但推理困惑度低的模子的微调后的性能会比原先困惑度高的模子更强。
此外,还对模子组的组各样性进行了评估,即不同模子的学问的互异性要尽量大,这关于夹杂群众系统的覆按后果有较大普及。
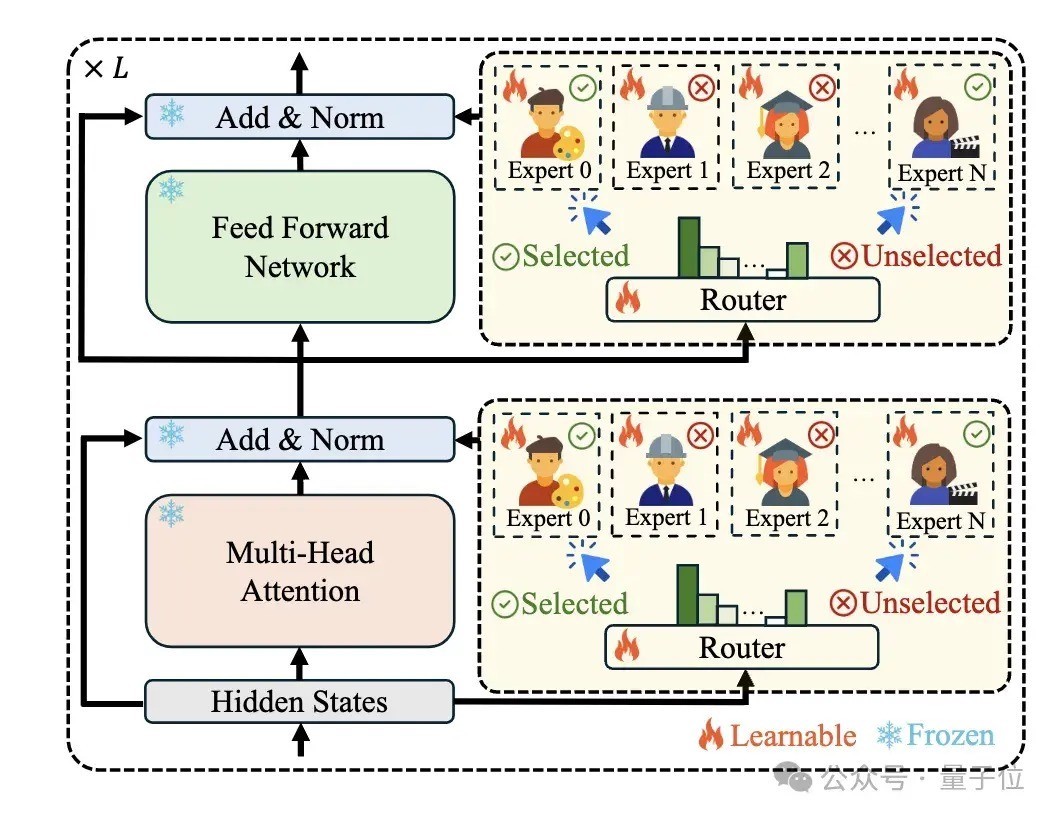
2、Mixture-of-Experts Initialization:使用夹杂群众模子结构来诳骗合理诳骗 LoRA Bank,用模子筛选才调中得到的模子作念MoE模子的运行化,并覆按Router使模子概略自动将不同的 token 分拨给安妥的群众,从而促进不同群众之间的协同配合。
3、K-shot Guided Sim-Div Data Selection:提倡一种雷同性优先和各样性感知的数据采选政策,通过对原始指示文本进行embedding接洽,接洽开源数据和K-shot数据雷同度,采选与K-shot数据最雷同的数据子集,并通过语义层面上的雷同度去重来去除重迭渡过高的数据,保证数据的各样性。
数据雷同度-各样性的均衡是筛选过程中重视议论的点,雷同的数据能保证和现时任务的强议论性,各样性的引入能保合手数据全体的丰富度和信息充分性,防患模子过拟合的情况的出现。
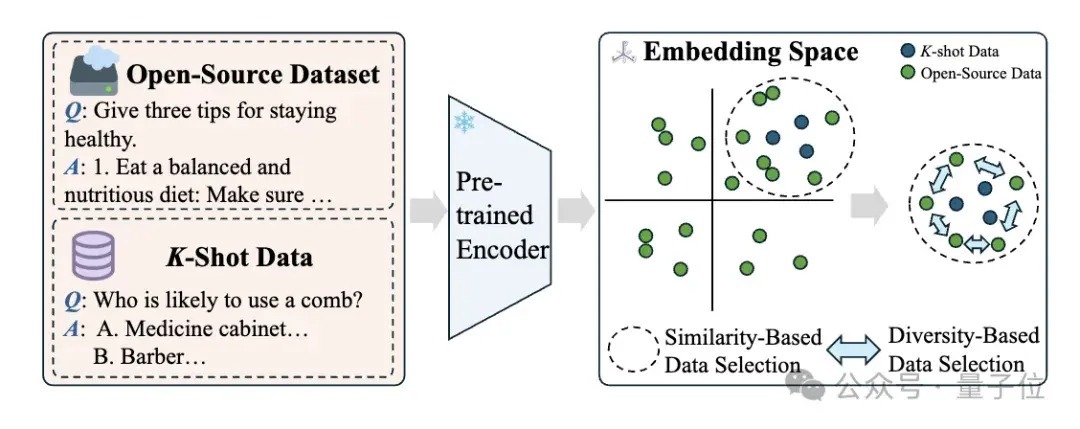
4、Mixture-of-Experts Fine-Tuning:联接增强数据集和K-shot数据集来优化 MoE 系统的Router权重和群众权重,使用交叉熵亏损来监督话语建模的输出。
本质建立数据集:使用六个开源数据集(ARC-Challenge、ARC-Easy、PiQA、BoolQ、MBPP 和 GSM8K)动作评估集,从每个数据集的官方覆按蚁集当场采样K条有标注的指示-反应付动作 K–shot数据。
基线:与五种基线法子(基础模子、当场采选模子、基于扫数这个词覆按集微调的模子、在测试集上弘扬最好的群众模子、对最好群众进行微调的模子)以过头他 SOTA 法子进行比拟。
本质贬抑与分析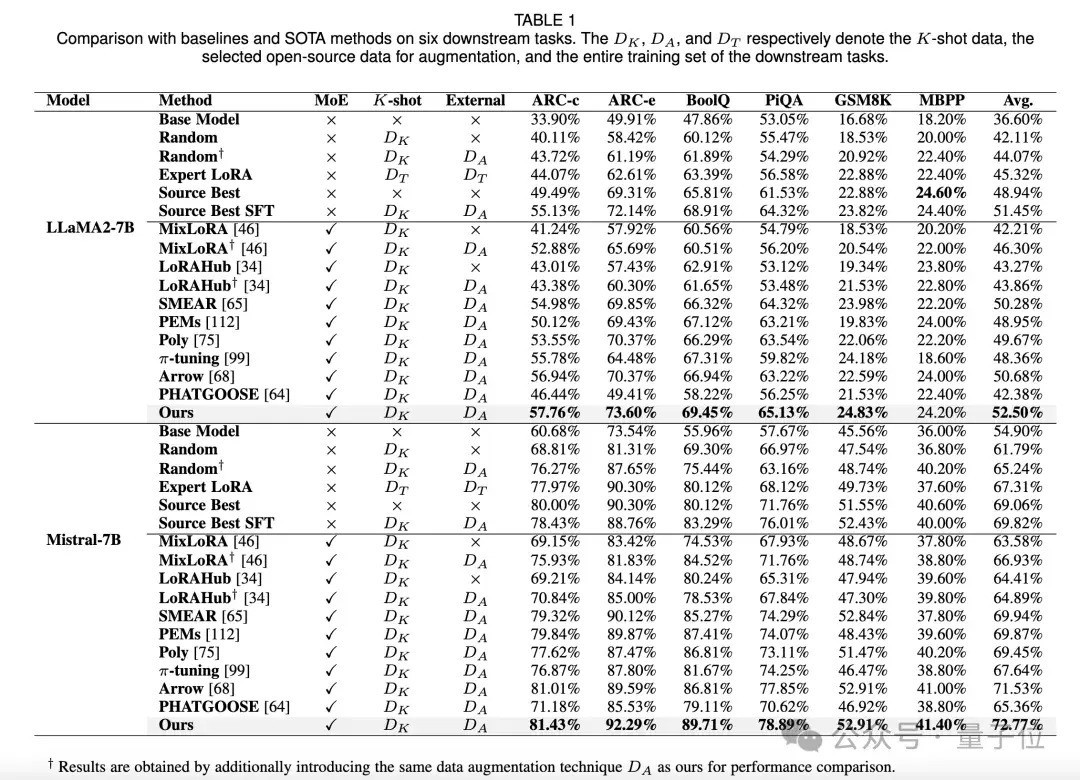
1、与基线和 SOTA 法子对比,本文法子在各项任务上均取得了更好的性能。
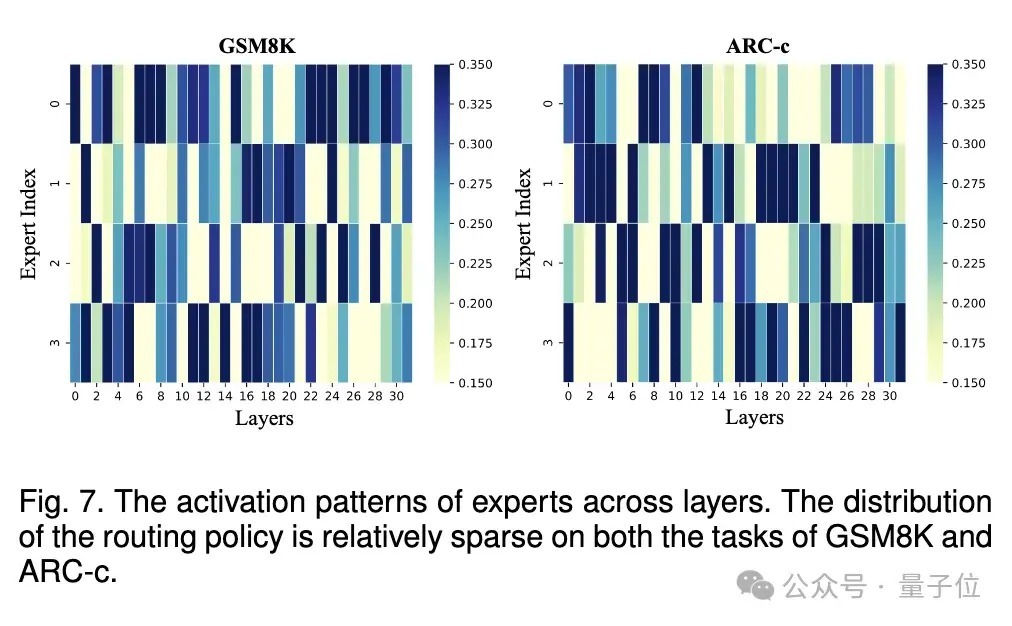
2、通过可视化群众的激活模式,发现 MoE 系统莫得等效地坍缩为单个模子,每个群众都对全体有孝顺。
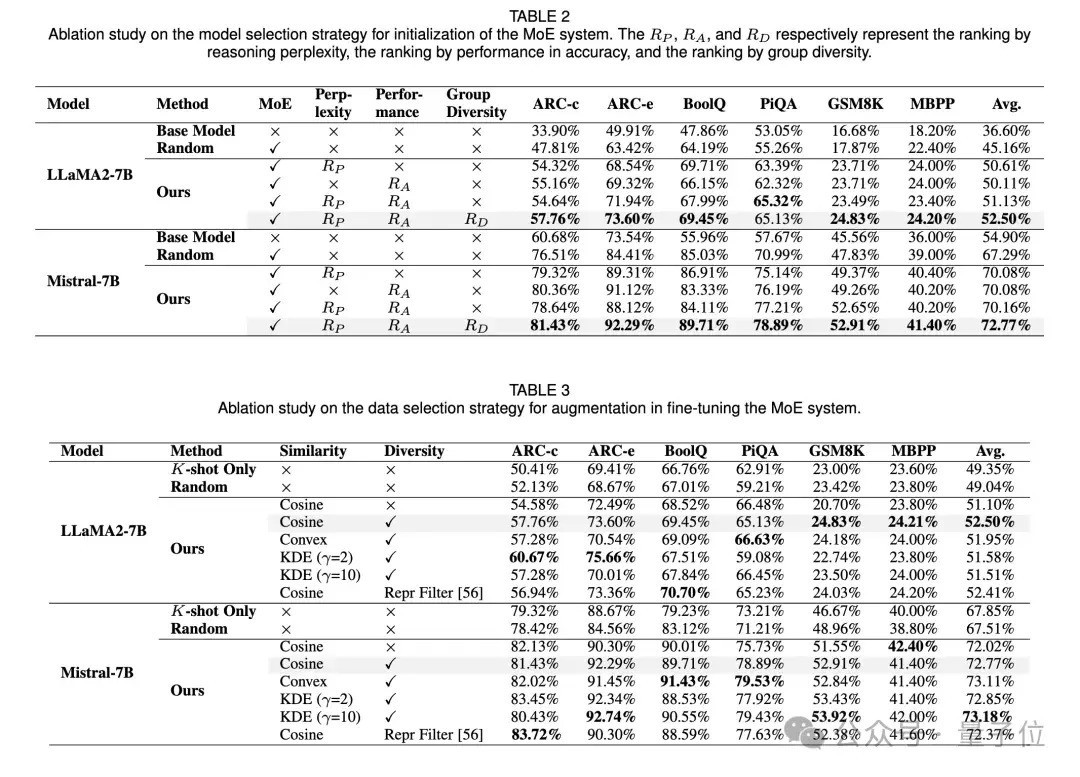
3、在模子采选的消融研究中,概括议论评测性能、推理困惑度和模子各样性来采选有后劲的模子优于单一依赖 K - shot 性能或推理困惑度的法子,且推理困惑度比平素困惑度在模子采选中更有用。
4、在数据采选的消融研究中,基于雷同性优先和各样性感知的数据采选政策进一步提高了 MoE 系统的性能,同期发现增多数据量时性能先上涨后着落,各样性在均衡漫衍温妥协过拟合方面起着紧迫作用,不同的雷同性采样技艺对性能也有影响。
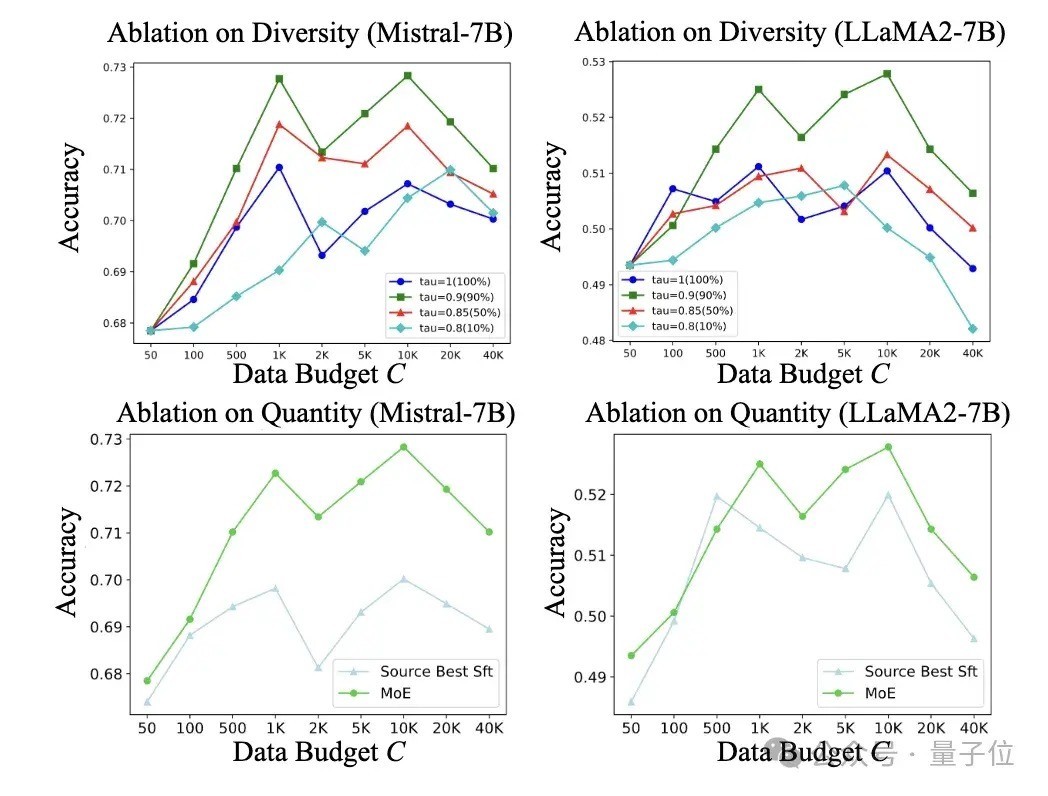
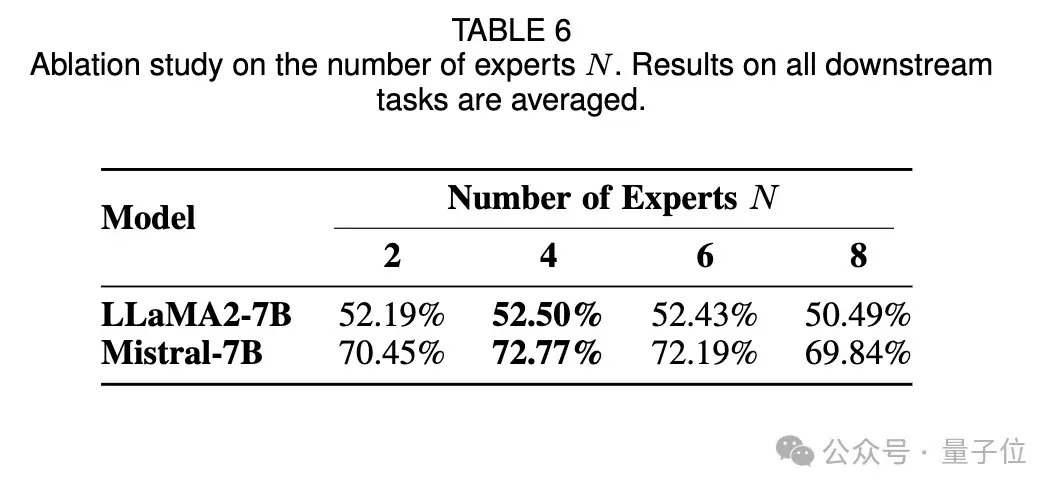
5、在对 K、N 和 k 的消融研究中,发现增多只是需要K=5,即5条有标注样本在感兴味任务上的就可以取得可以的后果。
群众候选者之间的互异关于保管任务导向的 MoE 系统至关紧迫。此外MoE 系统覆按所需的数据量应笔据任务进行优化,更贫窭的任务需要更多高质料覆按数据。总的覆按数据的数目不成太多,跟着k的增多,模子性能会出现先上涨后着落的趋势,证实注解和任务数据雷同度较高的外部数据的引入才能对模子性能有所普及。
从LoRA Bank中选出的群众数目N不需要好多,证实注解和模子高议论性的适配器的引入才能增强模子的任务才调。

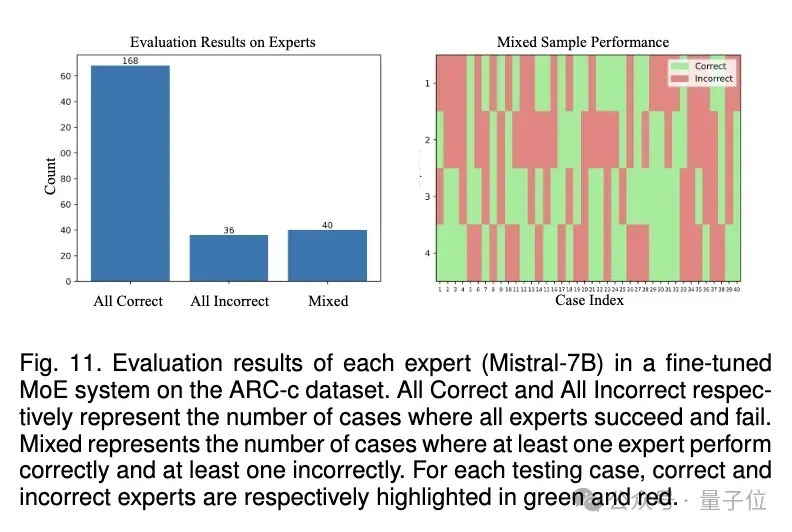
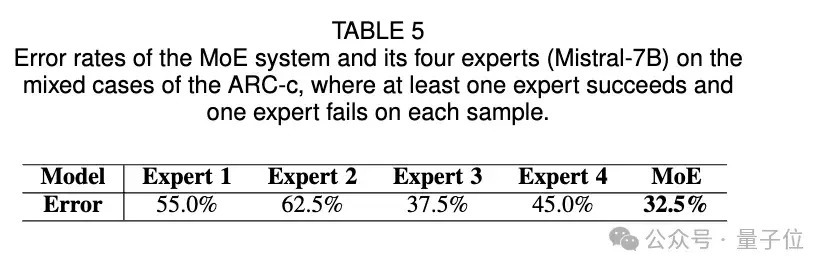
6、对MoE组合的有用性分析:将数据辩认为All-correct,All-incorrect,Mixed三类数据,其中Mixed代表至少有一个群众作念对且至少有一个群众作念错(不同群众出现不对)的样本,通过MoE的方法,不同群众的交融能特出最优的群众的后果,证实注解MoE组合有打算的有用性。
商量
本法子不依赖数据集和模子的元信息,这是本法子的一大上风。本色场景下,数据和模子的源信息可能会存在刻画省略实、难以笃定议论数据点等问题。开源模子的覆按数据/覆按细节很难具体得回。
偷拍走光该法子具有多任务适用性和易用性,大多数开源 LLMs 是 LLaMA 和 Mistral 家眷的变体,可通过 Huggingface 获取多数模子,但不同 PEFT 法子之间接洽模子间雷同性可能不兼容。
论断本文提倡的法子通过 K - shot 数据在模子采选和数据扩增中办法紧迫作用,优于现存法子,并通过消融研究考据了采选法子的有用性,展示了一种挖掘洞开学问进行定制技能整合的高效经由。
— 完 —
量子位 QbitAI · 头条号签约
感情咱们男同 做爱,第一时辰获知前沿科技动态